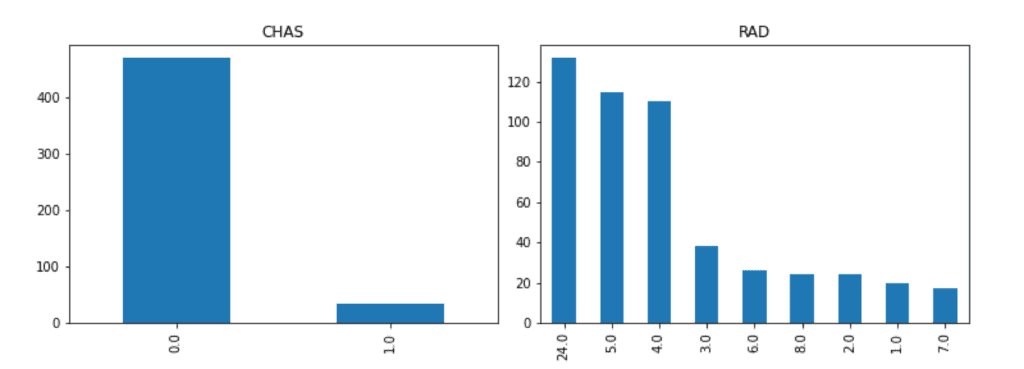
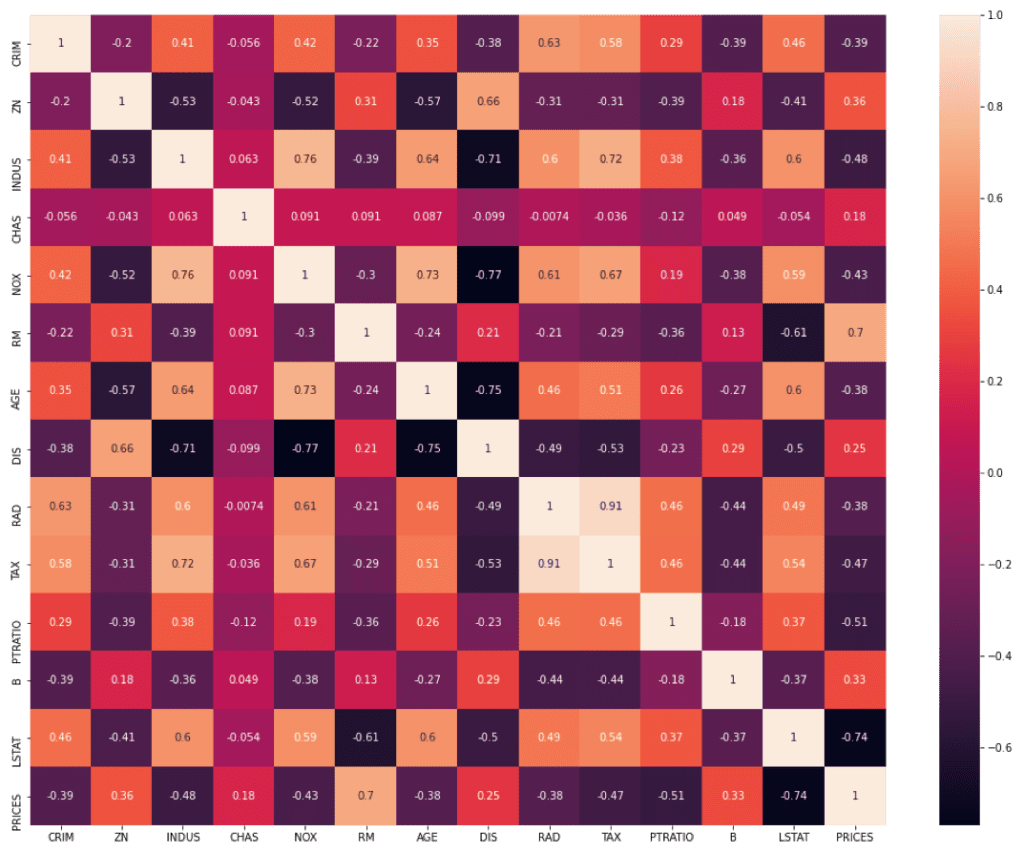
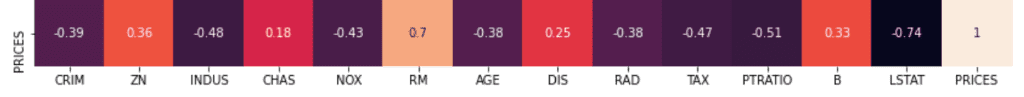The descriptive statistics have important information because they reflect a summary of a dataset. For example, from descriptive statistics, we can know the scale, variation, minimum and maximum values. If you know the above information, you can have a sense of grasping whether one of the data is large or small, or whether it deviates greatly from the average value.
In this post, we will see the descriptive statistics with a definition. Understanding statistical descriptions not only helps to develop a sense of a dataset but is also useful for understanding the preprocessing of a dataset.
The complete notebook can be found on GitHub.
Dataset
Here, we utilize the Boston house prices dataset for calculating the descriptive statistics, such as mean, variance, and standard deviation. The reason why we adopt this dataset is we can use it so easily with the scikit-learn library.
The code for using the dataset as Pandas DataFrame is as follows.
import numpy as np ##-- Numpy
import pandas as pd ##-- Pandas
import sklearn ##-- Scikit-learn
import matplotlib.pylab as plt ##-- Matplotlib
from sklearn.datasets import load_boston
dataset = load_boston()
df = pd.DataFrame(dataset.data)
df.columns = dataset.feature_names
df["PRICES"] = dataset.target
df.head()
>> CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT PRICES
>> 0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 24.0
>> 1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 21.6
>> 2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 34.7
>> 3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 33.4
>> 4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33 36.2The details of this dataset are introduced in another post below. In this post, let’s calculate the mean, the variance, the standard deviation for “df[“PRICES”]”, the housing prices.
Mean
The mean $\mu$ is the average of the data. It must be one of the most familiar concepts. However, the concept of mean is important because we can obtain the sense of whether one value of data is large or small. Such a feeling is important for a data scientist.
Now, assuming that $N$ data are $x_{1}$, $x_{2}$, …, $x_{n}$, the mean $\mu$ is defined by the following formula.
$$\begin{eqnarray*}
\mu
=
\frac{1}{N}
\sum^{N}_{i=1}
x_{i}
,
\end{eqnarray*}$$
where $x_{i}$ is the value of $i$-th data.
It may seem a little difficult when expressed in mathematical symbols. However, as you know, we just take a summation of all the data and divide it by the number of data. Once we defined the mean, we can define the variance.
Then, let’s calculate the mean of each column. We can easily calculate by the “mean()” method.
df.mean()
>> CRIM 3.613524
>> ZN 11.363636
>> INDUS 11.136779
>> CHAS 0.069170
>> NOX 0.554695
>> RM 6.284634
>> AGE 68.574901
>> DIS 3.795043
>> RAD 9.549407
>> TAX 408.237154
>> PTRATIO 18.455534
>> B 356.674032
>> LSTAT 12.653063
>> PRICES 22.532806
>> dtype: float64When you want the mean value of just one column, for example the “PRICES”, the code is as follows.
df["PRICES"].mean()
>> 22.532806324110677Variance
The variance $\sigma^{2}$ reflects the dispersion of data from the mean value. The definition is as follows.
$$\begin{eqnarray*}
\sigma^{2}
=
\frac{1}{N}
\sum^{N}_{i=1}
\left(
x_{i} – \mu
\right)^{2},
\end{eqnarray*}$$
where $N$, $x_{i}$, and $\mu$ are the number of the data, the value of $i$-th data, and the mean of $x$, respectively.
Expressed in words, the variance is the mean of the squared deviations from the mean of the data. It is no exaggeration to say that the information in the data exists in a variance! In other words, there is no worth to pay an attention to the data with the ZERO variance.
For example, let’s consider predicting math skills from exam scores. The exam scores of the person(A, B, and C) are like the below table.
| Person | Math | Physics | Chemistry |
| A | 100 | 90 | 60 |
| B | 60 | 70 | 60 |
| C | 20 | 40 | 60 |
From the above table, we can clearly see that those who are good at physics are also good at math. On the other hand, it is impossible to infer whether the person is good at mathematics from chemistry scores. Because all three scores equal the average score of 60. Namely, the variance of chemistry is ZERO!! This fact indicates that the scores of chemistry have no information, no worth to pay attention to. We should drop the “Chemistry” columns from the dataset when analyzing! This is one of the data preprocessing.
Then, let’s calculate the mean of each column of the Boston house prices dataset. We can easily calculate by the “var()” method.
df.var()
>> CRIM 73.986578
>> ZN 543.936814
>> INDUS 47.064442
>> CHAS 0.064513
>> NOX 0.013428
>> RM 0.493671
>> AGE 792.358399
>> DIS 4.434015
>> RAD 75.816366
>> TAX 28404.759488
>> PTRATIO 4.686989
>> B 8334.752263
>> LSTAT 50.994760
>> PRICES 84.586724
>> dtype: float64Standard Deviation
The standard deviation $\sigma$ is defined by the root of the variance as follows.
$$\begin{eqnarray*}
\sigma
=
\sqrt{
\frac{1}{N}
\sum^{N}_{i=1}
\left(
x_{i} – \mu
\right)^{2}
},
\end{eqnarray*}$$
where $N$, $x_{i}$, and $\mu$ are the number of the data, the value of $i$-th data, and the mean of $x$, respectively.
Why we introduced the standard deviation instead of the variance? This is because the unit becomes the same when we adopt the standard deviation of $\sigma$. Then, we can recognize $\sigma$ as the variation from the mean.
Then, let’s calculate the standard deviation of each column of the Boston house prices dataset. We can easily calculate by the “std()” method.
df.std()
>> CRIM 8.601545
>> ZN 23.322453
>> INDUS 6.860353
>> CHAS 0.253994
>> NOX 0.115878
>> RM 0.702617
>> AGE 28.148861
>> DIS 2.105710
>> RAD 8.707259
>> TAX 168.537116
>> PTRATIO 2.164946
>> B 91.294864
>> LSTAT 7.141062
>> PRICES 9.197104
>> dtype: float64In fact, at the stage of defining these three concepts, we can define the Gaussian distribution. However, I’ll introduce the Gaussian distribution in another post.
Other descriptive statistics are calculated in the same way, so carefully select the ones you use most often and list them below.
| Method | Description |
| mean | Average value |
| var | Variance value |
| std | Standard deviation value |
| min | Minimum value |
| max | Maximum value |
| median | Median value, the value at the center of the data |
| sum | Total value |
Confirm all at once
Pandas has the useful function “describe()”, which describes the basic descriptive statistics. The “describe()” method is very convenient to use as a starting point.
df.describe()
>> CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT PRICES
>> count 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000 506.000000
>> mean 3.613524 11.363636 11.136779 0.069170 0.554695 6.284634 68.574901 3.795043 9.549407 408.237154 18.455534 356.674032 12.653063 22.532806
>> std 8.601545 23.322453 6.860353 0.253994 0.115878 0.702617 28.148861 2.105710 8.707259 168.537116 2.164946 91.294864 7.141062 9.197104
>> min 0.006320 0.000000 0.460000 0.000000 0.385000 3.561000 2.900000 1.129600 1.000000 187.000000 12.600000 0.320000 1.730000 5.000000
>> 25% 0.082045 0.000000 5.190000 0.000000 0.449000 5.885500 45.025000 2.100175 4.000000 279.000000 17.400000 375.377500 6.950000 17.025000
>> 50% 0.256510 0.000000 9.690000 0.000000 0.538000 6.208500 77.500000 3.207450 5.000000 330.000000 19.050000 391.440000 11.360000 21.200000
>> 75% 3.677083 12.500000 18.100000 0.000000 0.624000 6.623500 94.075000 5.188425 24.000000 666.000000 20.200000 396.225000 16.955000 25.000000
>> max 88.976200 100.000000 27.740000 1.000000 0.871000 8.780000 100.000000 12.126500 24.000000 711.000000 22.000000 396.900000 37.970000 50.000000Note that,
“count”: Number of the data for each columns
“25%”: Value at the 25% position of the data
“50%”: Value at the 50% position of the data, equaling to “Median”
“75%”: Value at the 25% position of the data
Summary
We have seen the brief explanation of the basic descriptive statistics and how to calculate them. Understanding the concept of descriptive statistics is essential to understand the dataset. You should note the fact in your memory that the information of the dataset is included in the descriptive statistics.
The author hopes this blog helps readers a little.